全国统一销售热线




地址:广东省清远市
电话:0898-08980898
传真:000-000-0000
邮箱:admin@youweb.com
更新时间:2024-03-12 11:54:41
目前训练超大规模语言模型主要有两条技术路线:TPU + XLA + TensorFlow/JAX 和 GPU + PyTorch + Megatron-LM + DeepSpeed。前者由Google主导,由于TPU和自家云平台GCP深度绑定,对于非Googler来说, 只可远观而不可把玩,后者背后则有NVIDIA、Meta、MS大厂加持,社区氛围活跃,也更受到群众欢迎。
上面提到的DeepSpeed的核心是ZeRO(Zero Redundancy Optimizer),简单来说,它是一种显存优化的数据并行(data parallelism, DP)方案。而“优化“这个话题又永无止境,在过去两年DeepSpeed团队发表了三篇ZeRO相关的论文,提出了去除冗余参数、引入CPU和内存、引入NVMe等方法,从始至终都围绕着一个目标:将显存优化进行到底。
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models 发表在SC 20,DeepSpeed项目最初就是论文中ZeRO方法的官方实现。
如今训练大模型离不开各种分布式并行策略,常用的并行策略包括:
# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1
GPU1:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
a1 | b1 | c1# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有三层:L0, L1, L2
# 每层有两个神经元
# 两张卡
GPU0:
L0 | L1 | L2
---|----|---
a0 | b0 | c0
GPU1:
L0 | L1 | L2
---|----|---
a1 | b1 | c1# https://huggingface.co/docs/transformers/parallelism#model-parallelism
# 假设模型有8层
# 两张卡
====================== =====================
| L0 | L1 | L2 | L3 | | L4 | L5 | L6 | L7 |
====================== =====================
GPU0 GPU1
# 设想一下,当GPU0在进行(前向/后向)计算时,GPU1在干嘛?闲着
# 当GPU1在进行(前向/后向)计算时,GPU0在干嘛?闲着
# 为了防止”一卡工作,众卡围观“,实践中PP也会把batch数据分割成
# 多个micro-batch,流水线执行其中数据并行由于简单易实现,应用最为广泛,当然这不表示它没有”缺点“,每张卡都存储一个模型,此时显存就成了模型规模的天花板。如果我们能减少模型训练过程中的显存占用,那不就可以训练更大的模型了?一个简单的观察是,如果有2张卡,那么系统中就存在2份模型参数,如果有4张卡,那么系统中就存在4份模型参数,如果有N张卡,系统中就存在N份模型参数,其中N-1份都是冗余的,我们有必要让每张卡都存一个完整的模型吗?系统中能否只有一个完整模型,每张卡都存 参数,卡数越多,每张卡的显存占用越少,这样越能训练更大规模的模型。
下面就让我们看一下ZeRO是如何去除数据并行中的冗余参数。
注:对于LLMs动辄几百上千亿参数,实践中往往是3种并行策略混用,也就是论文中经常提到的3D parallelism,不过Google家的TPU Pod可以堆积几千张芯片,带宽也夸张,甚至不需要PP就可以训练LLMs。
混合精度训练(mixed precision training)和Adam优化器基本上已经是训练语言模型的标配,我们先来简单回顾下相关概念。
Adam在SGD基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)[1]。
混合精度训练,字如其名,同时存在fp16和fp32两种格式的数值,其中模型参数、模型梯度都是fp16,此外还有fp32的模型参数,如果优化器是Adam,则还有fp32的momentum和variance。
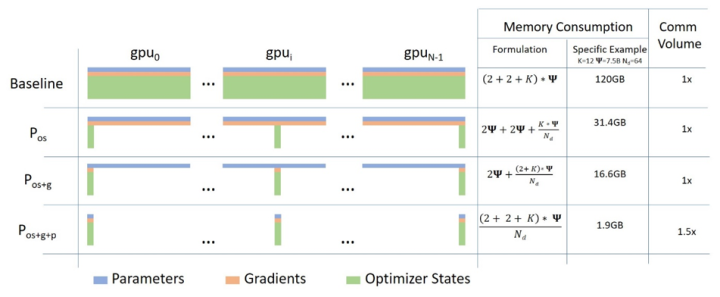
ZeRO将模型训练阶段,每张卡中显存内容分为两类:
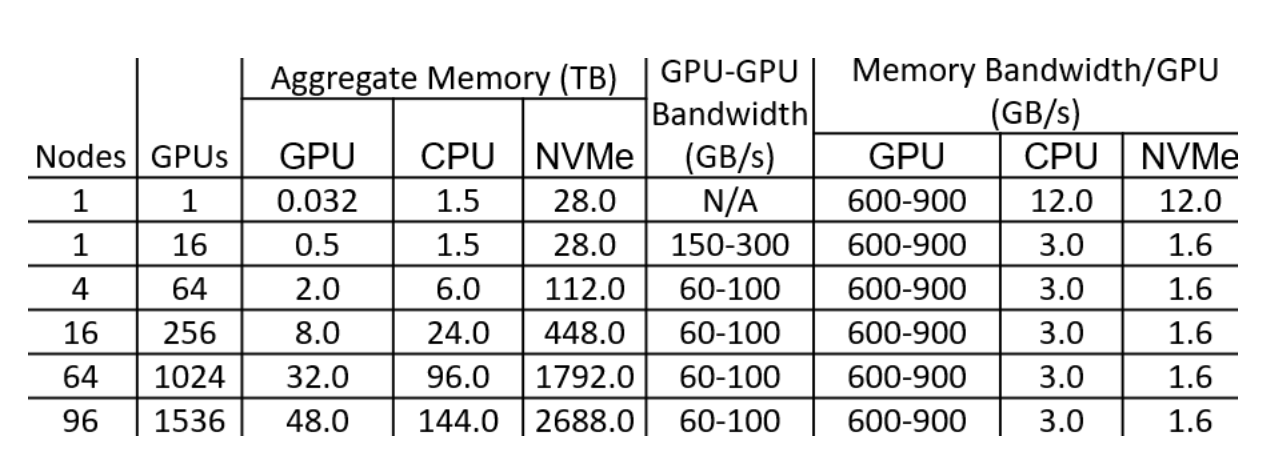
来看一个例子,GPT-2含有1.5B个参数,如果用fp16格式,只需要3GB显存,但是模型状态实际上需要耗费24GB!相比之下,激活值可以用activation checkpointing来大大减少,所以模型状态就成了头号显存杀手,它也是ZeRO的重点优化对象。而其中Adam状态又是第一个要被优化的。
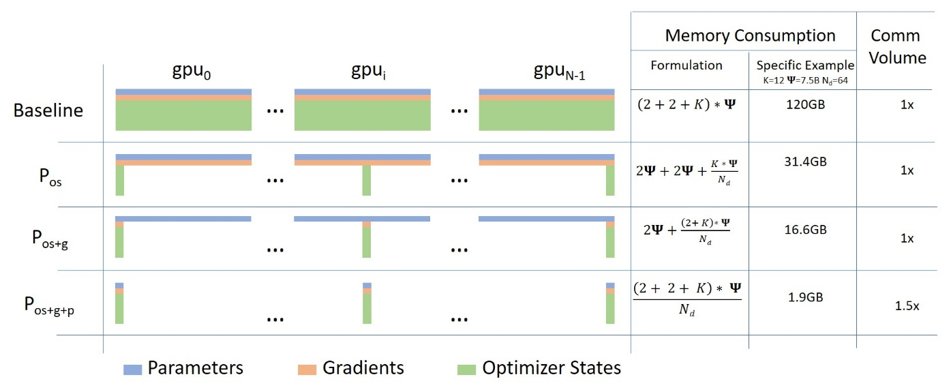
针对模型状态的存储优化(去除冗余),ZeRO使用的方法是分片(partition),即每张卡只存 的模型状态量,这样系统内只维护一份模型状态。
下图中Memory Consumption 第二列给出了一个示例: ,可以看到显存优化相当明显。
在DeepSpeed中, 对应ZeRO-1,
对应ZeRO-2,
对应ZeRO-3,一般使用ZeRO-1就足够了。
解决了模型状态,再来看剩余状态,也就是激活值(activation)、临时缓冲区(buffer)以及显存碎片(fragmentation)。
上面的方案对于显存优化看起来很有效,但是还有一个疑问,相比于传统的数据并行,ZeRO是否会带来额外的通信(communication)成本?特别是在大规模训练场景下,通信本来就容易成为瓶颈,如果ZeRO舍本逐末,我想大家是不能接受的。

在分析之前,我们先回顾下常用的集合通信(collective communication)函数Collective Operations。
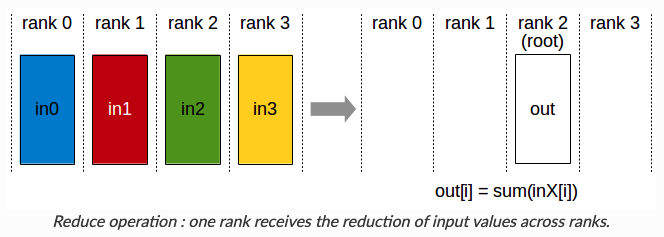
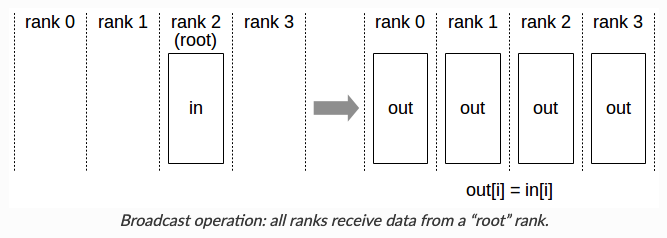
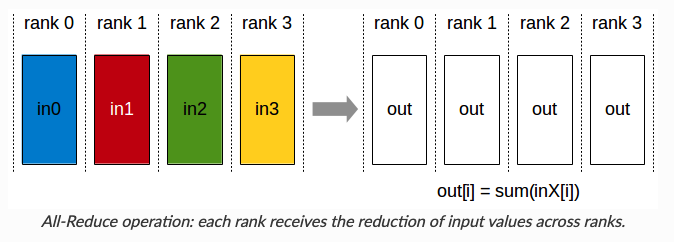
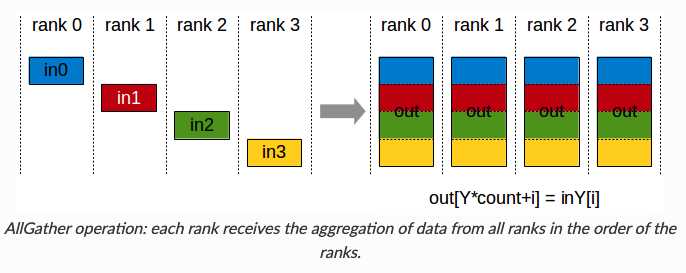
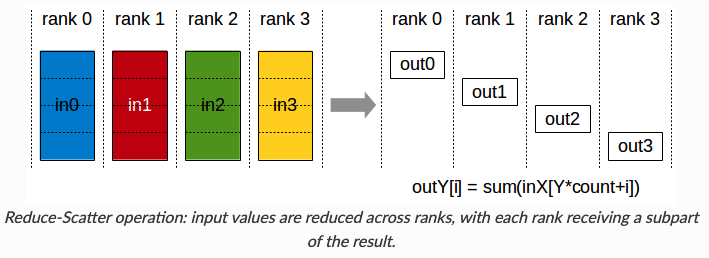
下面我们就分析下通信数据量,先说结论, 和
的通信量和传统数据并行相同,
会增加通信量。
传统数据数据并行在每一步(step/iteration)计算梯度后,需要进行一次AllReduce操作来计算梯度均值,目前常用的是Ring AllReduce,分为ReduceScatter和AllGather两步,每张卡的通信数据量(发送+接受)近似为 [2]。
我们直接分析 ,每张卡只存储
的优化器状态和梯度,对于
来说,为了计算它这
梯度的均值,需要进行一次Reduce操作,通信数据量是
,然后其余显卡则不需要保存这部分梯度值了。实现中使用了bucket策略,保证
的梯度每张卡只发送一次。
这里还要注意一点,假如模型最后两层的梯度落在,为了节省显存,其他卡将这两层梯度删除,怎么计算倒数第三层的梯度呢?还是因为用了bucket,其他卡可以将梯度发送和计算倒数第三层梯度同时进行,当二者都结束,就可以放心将后两层梯度删除了。
当 计算好梯度均值后,就可以更新局部的优化器状态(包括
的参数),当反向传播过程结束,进行一次Gather操作,更新
的模型参数,通信数据量是
。
从全局来看,相当于用Reduce-Scatter和AllGather两步,和数据并行一致。
使得每张卡只存了
的参数,不管是在前向计算还是反向传播,都涉及一次Broadcast操作。
实验方面,“仅”使用400张V100就能训练170B的模型,是Megatron-LM的8倍(因为只用了 )。
ZeRO-Offload: Democratizing Billion-Scale Model Training发表在ATC 21,一作是来自UC Merced的Jie Ren,博士期间的研究方向是 Memory Management on Heterogeneous Memory Systems for Machine Learning and HPC. 所以看到这个题目也就不奇怪了。
ZeRO说到底是一种数据并行方案,可是很多人只有几张甚至一张卡,难道我们就没有梦想,我们就不想训练大模型吗:(

一张卡训不了大模型,根因是显存不足,ZeRO-Offload的想法很简单:显存不足,内存来补。
直接看下效果,在单张V100的情况下,用PyTorch能训练1.4B的模型,吞吐量是30TFLOPS,有了ZeRO-Offload加持,可以训练10B的模型,并且吞吐量40TFLOPS。这么好的效果能不能扩展到多卡上面呢,能啊,比如只用一台DGX-2服务器,可以训练70B的模型,是原来只用模型并行的4.5倍,在128张显卡的实验上基本也是线性加速,此外还可以与模型并行配合,快乐加倍:)
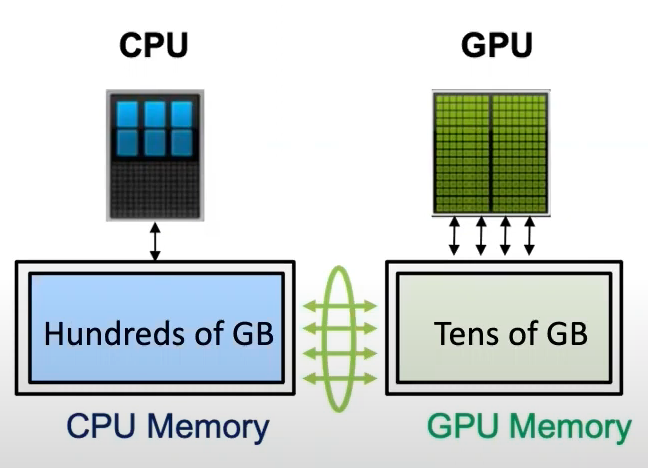
相比于昂贵的显存,内存廉价多了,能不能在模型训练过程中结合内存呢?其实已经有很多工作了,但是他们几乎只聚焦在内存上面,没有用到CPU计算,更没有考虑多卡的场景。ZeRO-Offload则将训练阶段的某些模型状态下放(offload)到内存以及CPU计算。
注:ZeRO-Offload没有涉及剩余状态(比如激活值)的下放,因为在Transformer LM场景中,他比模型状态占用的显存小。
ZeRO-Offload要做的事情我们清楚了,那么如何设计高效的offload策略呢?
ZeRO-Offload并不希望为了最小化显存占用而让系统的计算效率下降,否则的话,我们只用CPU和内存不就得了。但是将部分GPU的计算和存储下放到CPU和内存,必然涉及CPU和GPU之间的通信增加,不能让通信成为瓶颈,此外GPU的计算效率相比于CPU也是数量级上的优势,也不能让CPU参与过多计算,避免成为系统瓶颈,只有前两条满足的前提下,再考虑最小化显存的占用。
为了找到最优的offload策略,作者将模型训练过程看作数据流图(data-flow graph)。
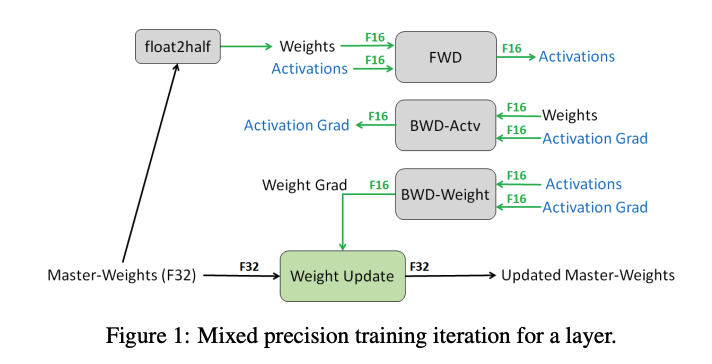
下图是某一层的一次迭代过程(iteration/step),使用了混合精读训练,前向计算(FWD)需要用到上一次的激活值(activation)和本层的参数(parameter),反向传播(BWD)也需要用到激活值和参数计算梯度,
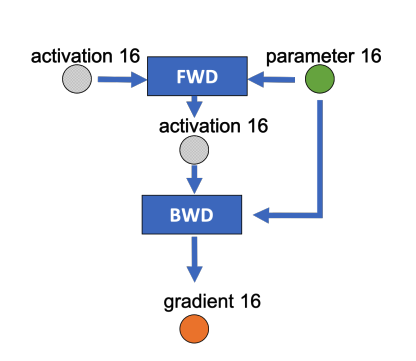
如果用Adam优化器进行参数更新(Param update),流程如下:
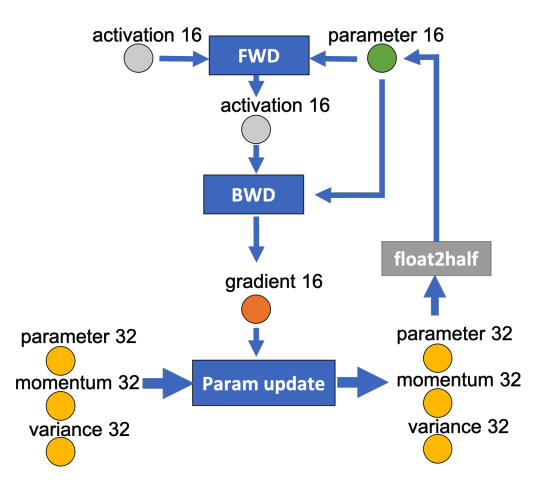
下面我们为边添加权重,物理含义是数据量大小(单位是字节),假设模型参数量是 ,在混合精度训练的前提下,边的权重要么是2M(fp16),要么是4M(fp32),
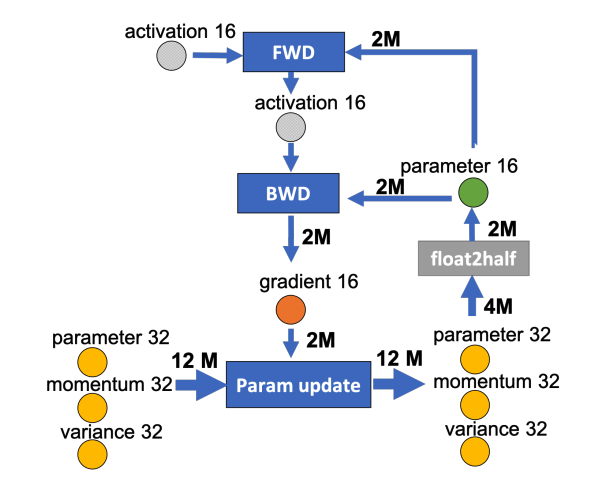
我们现在要做的就是沿着边把数据流图切分为两部分,分布对应GPU和CPU,计算节点(矩形节点)落在哪个设备,哪个设备就执行计算,数据节点(圆形)落在哪个设备,哪个设备就负责存储,将被切分的边权重加起来,就是CPU和GPU的通信数据量。
ZeRO-Offload的切分思路是:
图中有四个计算类节点:FWD、BWD、Param update和float2half,前两个计算复杂度大致是 ,
是batch size,后两个计算复杂度是
。为了不降低计算效率,将前两个节点放在GPU,后两个节点不但计算量小还需要和Adam状态打交道,所以放在CPU上,Adam状态自然也放在内存中,为了简化数据图,将前两个节点融合成一个节点FWD-BWD Super Node,将后两个节点融合成一个节点Update Super Node。如下图右边所示,沿着gradient 16和parameter 16两条边切分。
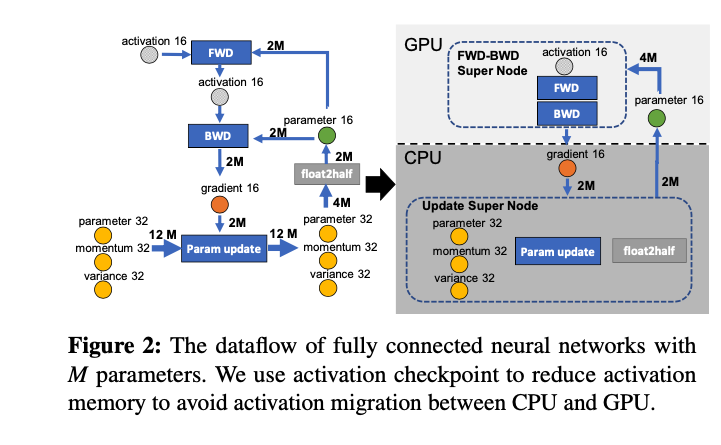
现在的计算流程是,在GPU上面进行前向和后向计算,将梯度传给CPU,进行参数更新,再将更新后的参数传给GPU。为了提高效率,可以将计算和通信并行起来,GPU在反向传播阶段,可以待梯度值填满bucket后,一遍计算新的梯度一遍将bucket传输给CPU,当反向传播结束,CPU基本上已经有最新的梯度值了,同样的,CPU在参数更新时也同步将已经计算好的参数传给GPU,如下图所示。
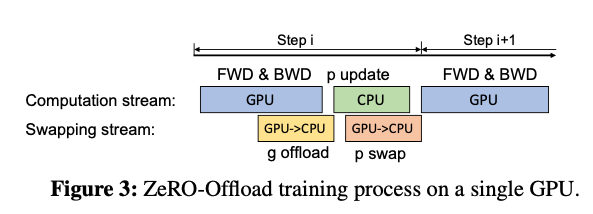
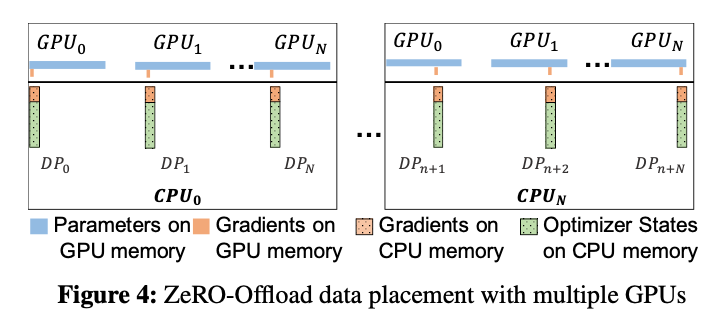
到目前为止,说的都是单卡场景,卡多的人表示。。。

在多卡场景,ZeRO-Offload利用了ZeRO-2,回忆下ZeRO-2是将Adam状态和梯度进行了分片,每张卡只保存 ,而ZeRO-Offload做的同样是将这
的Adam状态和梯度都offload到内存,在CPU上进行参数更新。
注意:在多卡场景,利用CPU多核并行计算,每张卡至少对应一个CPU进程,由这个进程负责进行局部参数更新。
并且CPU和GPU的通信量和 无关,因为传输的是fp16 gradient和fp16 parameter,总的传输量是固定的,由于利用多核并行计算,每个CPU进程只负责
的计算,反而随着卡数增加节省了CPU计算时间。
直接看下效果吧,

但是有一个问题,当batch size很小时,GPU上每个micro-batch计算很快,此时CPU计算时长会成为训练瓶颈,一种方法是让CPU在某个节点更新参数时延迟一步,后面就可以让GPU和CPU并行起来。
前N-1步,不进行延迟,避免早期训练不稳定,模型无法收敛,在第N步,CPU拿到GPU计算的梯度后,不更新参数,相当于GPU空算了一步,到N+1步,CPU开始根据刚才拿到的第N步的梯度计算,此时GPU开始算N+1步的梯度。
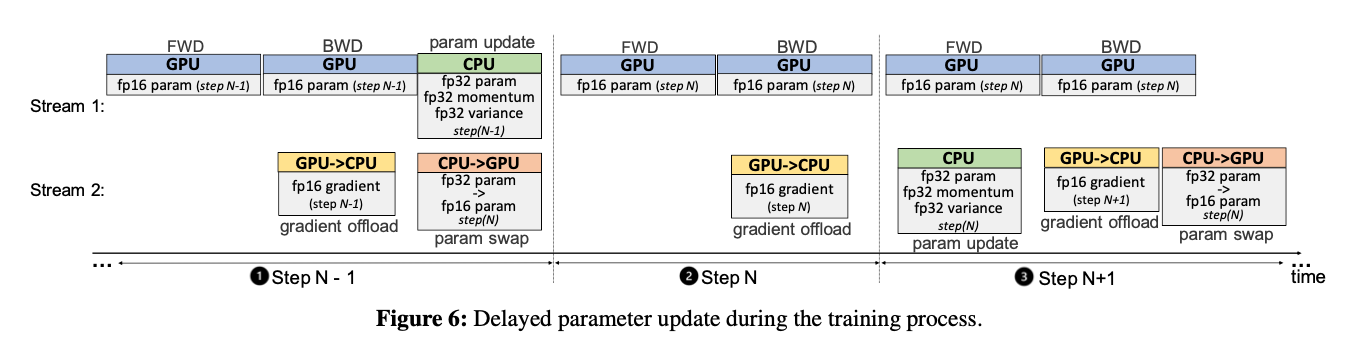
当然这样会有一个问题,用来更新参数的梯度并不是根据当前模型状态计算得到的,论文的实验结果表明暂未发现对收敛和效果产生影响。
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning 发表在SC 21,同样是进行offload,ZeRO-Offload更侧重单卡场景,而ZeRO-Infinity则是典型的工业界风格,奔着极大规模训练去了。
从GPT-1到GPT-3,两年时间内模型参数0.1B增加到175B,而同期,NVIDIA交出的成绩单是从V100的32GB显存增加A100的80GB,显然,显寸的提升速度远远赶不上模型模型增长的速度,这就是内存墙问题
https://zhuanlan.zhihu.com/p/363041668